|
Abdulkadir Gokce I am a second-year Ph.D. student in Computer Science at the Swiss Federal Institute of Technology Lausanne (EPFL), where I am advised by Martin Schrimpf. My research focuses on building artificial models of perception. Previously, I earned my master's degree at EPFL and my bachelor's in Electrical & Electronics Engineering and Mathematics at Bogazici University. I was fortunate to gain research experience at ETH Zurich, MIT, and Nanyang Technological University (NTU). Email / Google Scholar / Github / Twitter / Bluesky |

|
ResearchMy research investigates the extent to which current deep learning models can capture neural and behavioral signals, and aims to develop new modeling strategies that expand these capabilities. I am particularly focused on building scalable, multimodal models of human perception that integrate diverse neurocognitive datasets. |
First-Authored Papers* indicates equal contribution. |
|
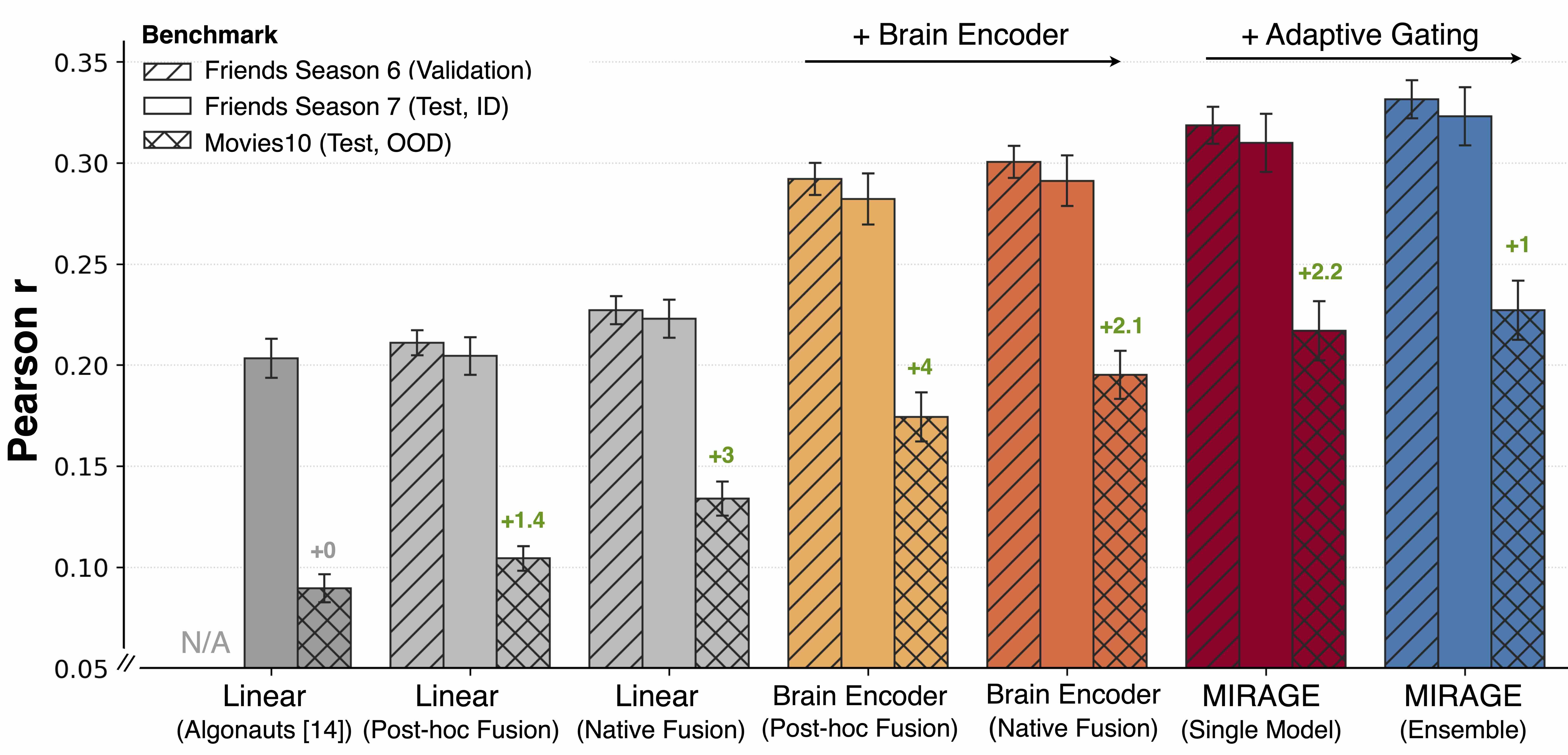
MIRAGE: Adaptive Multimodal Gating for Whole-Brain fMRI Encoding
Abdulkadir Gokce*, Badr AlKhamissi*, Martin Schrimpf Preprint, 2026 We introduced MIRAGE, a whole-brain fMRI encoding framework that combines a native multimodal foundation model with adaptive layer gating, achieving state-of-the-art prediction of brain responses to naturalistic movies. |
|
Multimodal Scaling Laws for Task & Data-Optimized Models of Visual Cortex
Abdulkadir Gokce, Yingtian Tang, Martin Schrimpf ICML, 2026 We mapped the scaling laws of brain alignment across vision models and neural recordings, showing that bigger pretraining helps only up to a point, after which neural supervision and improved mappings become the main drivers of progress. |
|
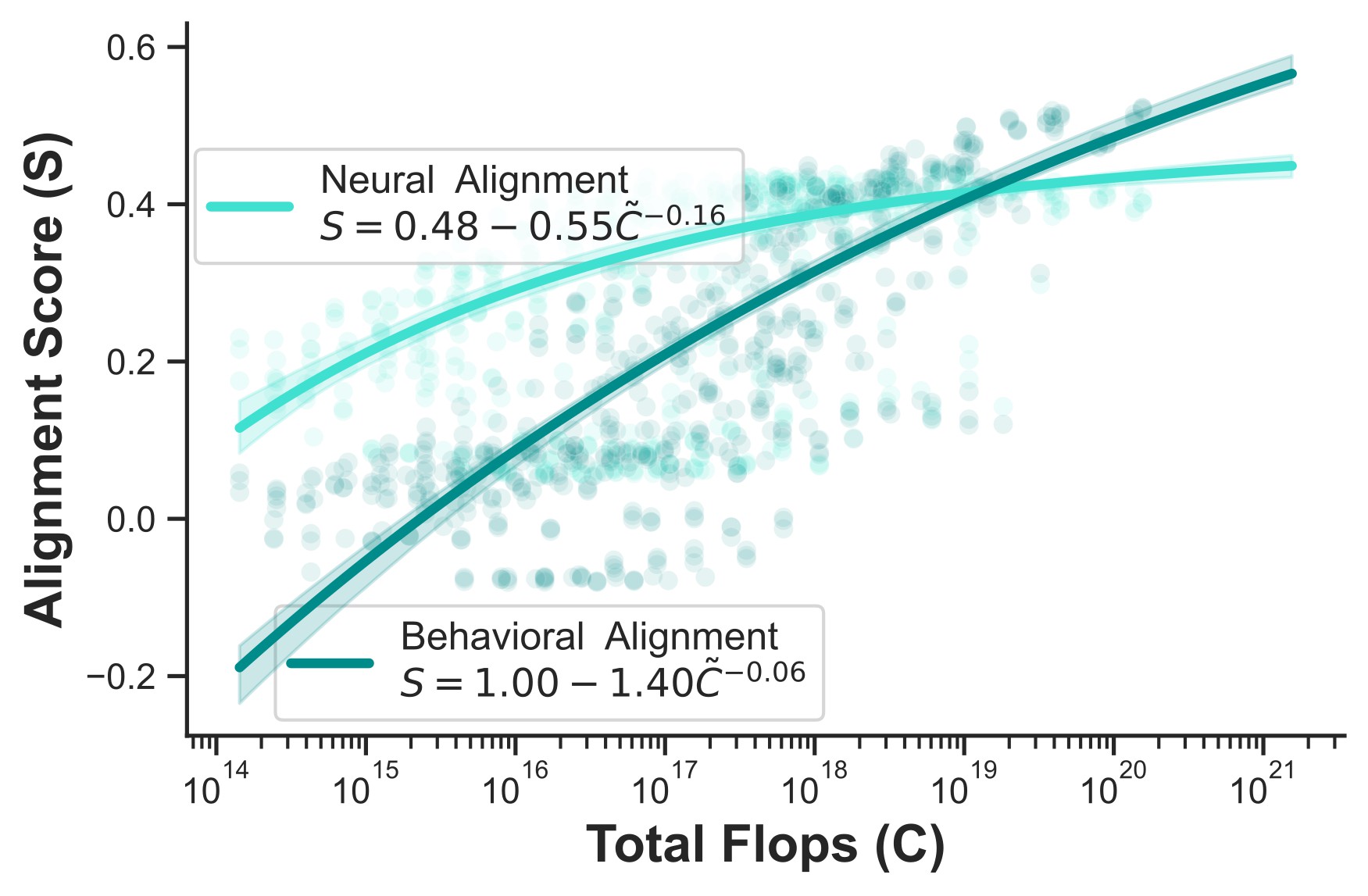
Scaling Laws for Task-Optimized Models of the Primate Visual Ventral Stream
Abdulkadir Gokce, Martin Schrimpf ICML, 2025 [Spotlight, Top 3%] We systematically explored scaling laws for primate vision models and discovered that neural alignment stops improving beyond a certain scale, even though behavior keeps aligning better. |
|
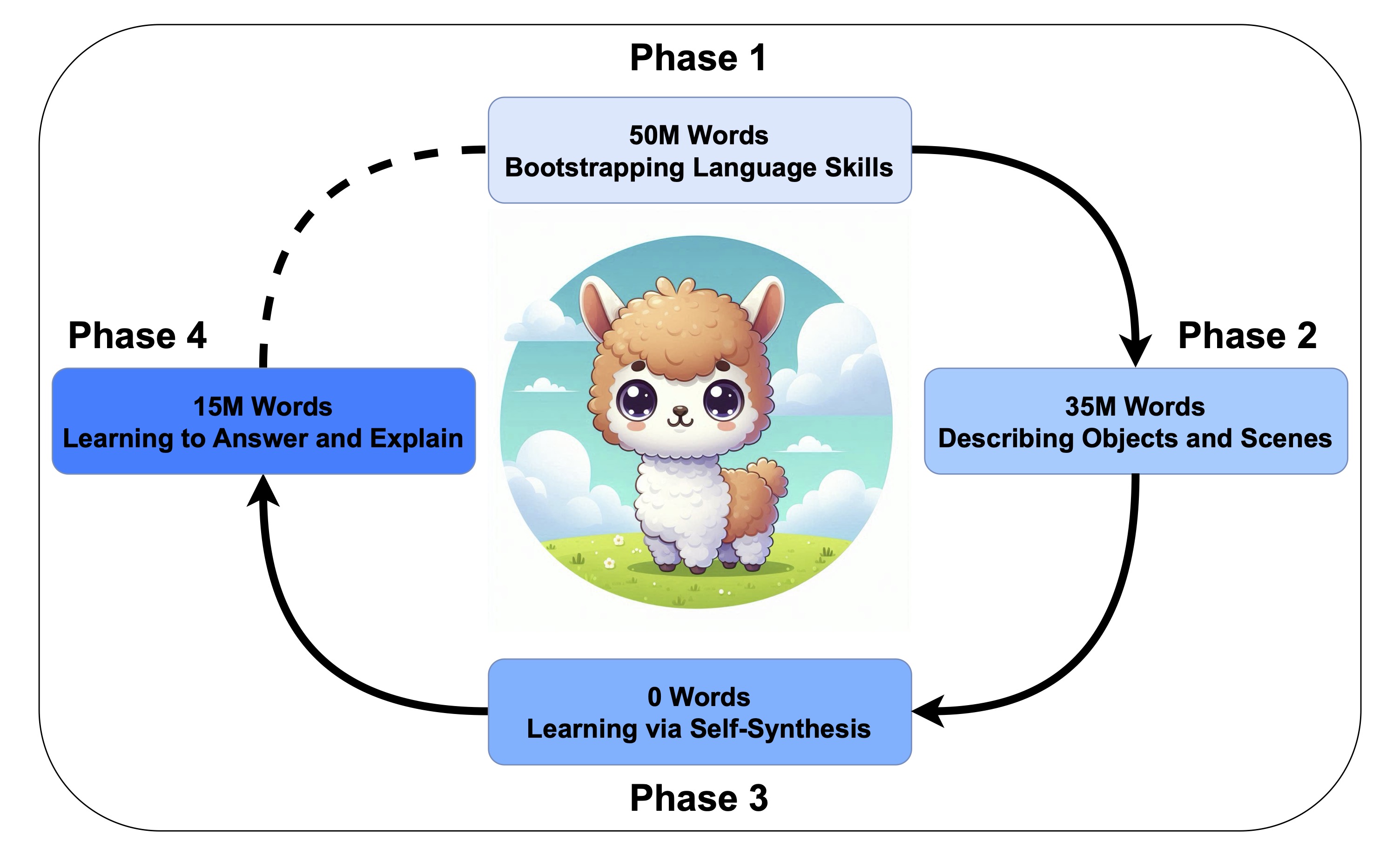
Dreaming Out Loud: A Self-Synthesis Approach For Training Vision-Language Models With Developmentally Plausible Data
Badr AlKhamissi*, Yingtian Tang*, Abdulkadir Gokce*, Johannes Mehrer, Martin Schrimpf BabyLM Challenge, at CoNLL 2024 Inspired by human cognitive development, our BabyLLaMA model learns language and vision jointly through a self-synthesis loop, generating its own training data from unlabeled images. |
Co-Authored Papers |
|
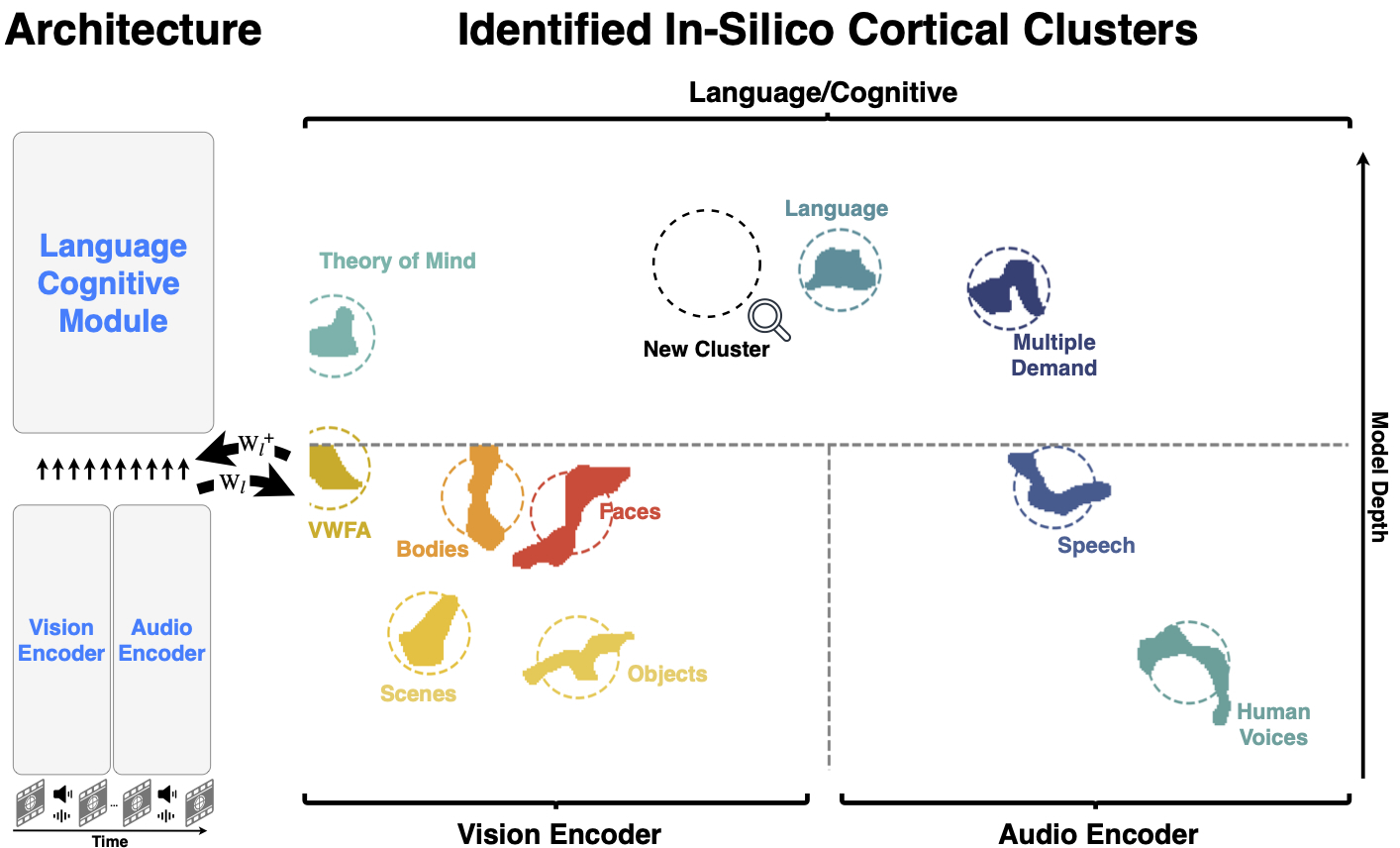
Discovering Functionally Selective Brain Regions with a Deep Topographic Multimodal Model
Badr AlKhamissi*, Johannes Mehrer*, Lara Marinov, Ahmed Abdelaal, Abdulkadir Gokce, Martin Schrimpf Preprint, 2026 We built Topo-Omni, a multimodal topographic model that unifies vision, audition, and language under a single spatial-smoothness objective, giving rise to brain-like functional clusters whose perturbation reproduces human-like behavioral effects. |
|
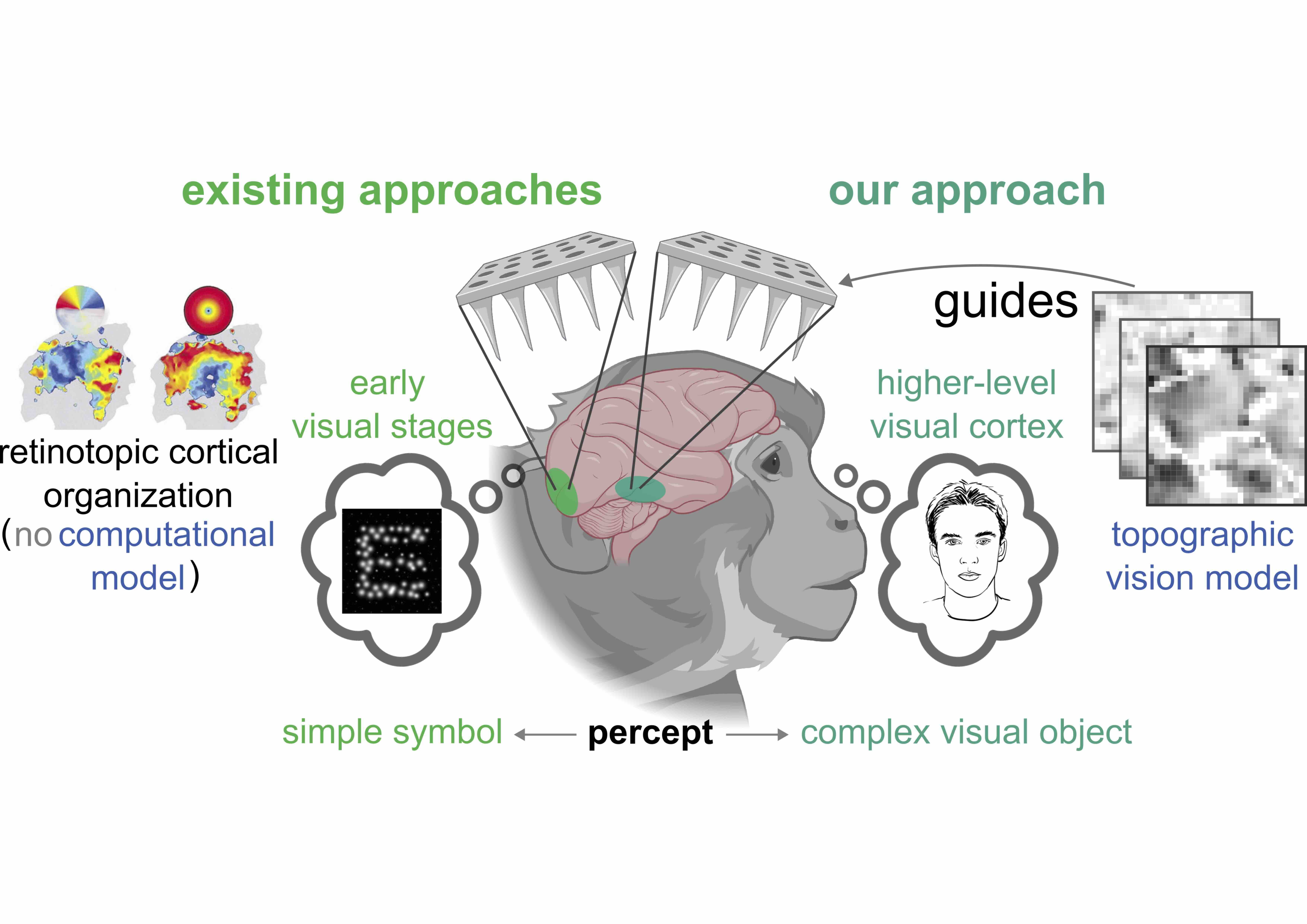
Model-Guided Microstimulation Steers Primate Visual Behavior
Johannes Mehrer, Ben Lonnqvist, Anna Mitola, Abdulkadir Gokce, Paolo Papale, Martin Schrimpf ICLR, 2026 We developed a model-guided framework that predicts and controls how microstimulation in primate visual cortex biases perceptual choices, showing strong correlation between model predictions and behavioral changes in macaque monkeys performing visual recognition tasks. |
|
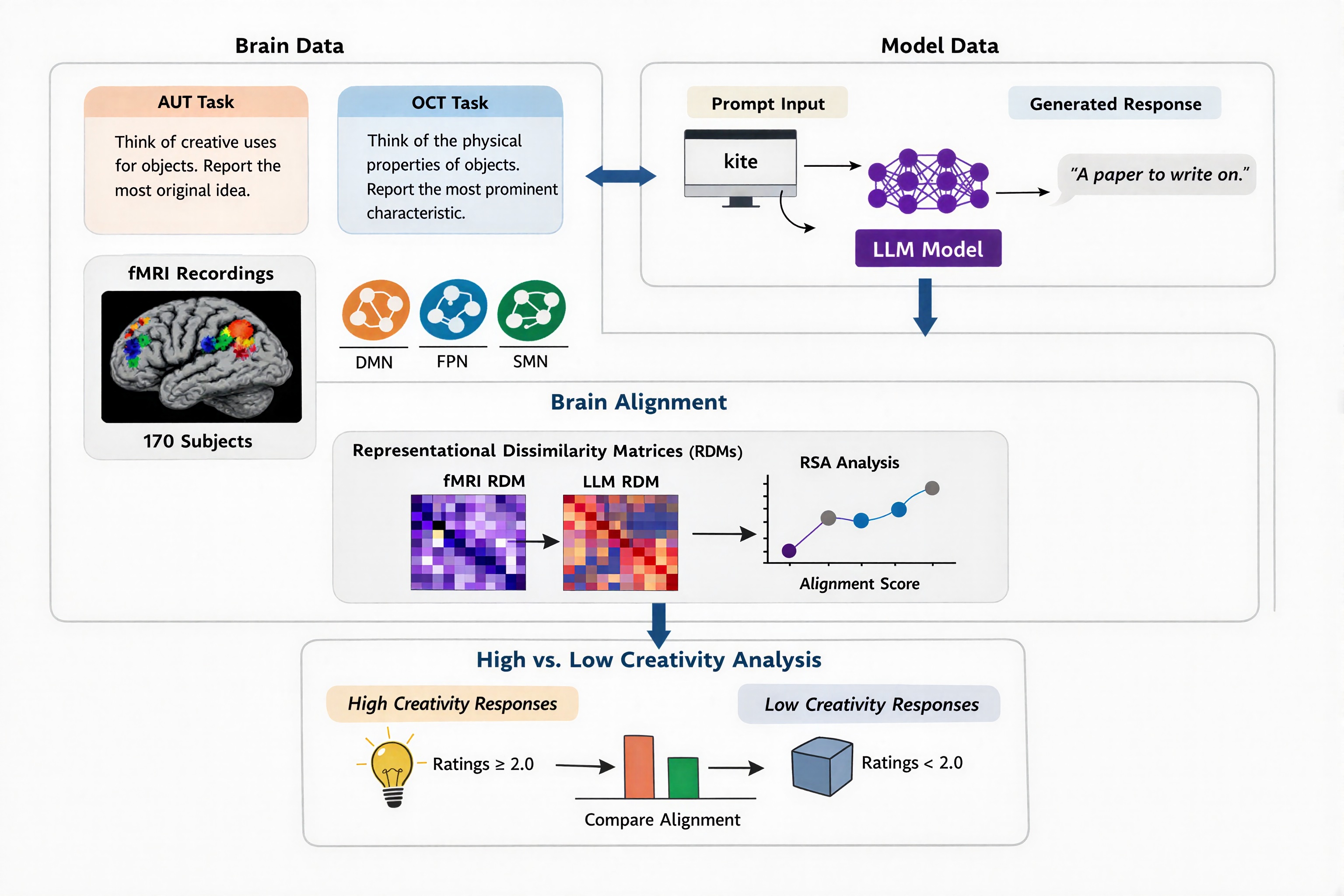
Large Language Models Align with the Human Brain during Creative Thinking
Mete Ismayilzada, Simone A. Luchini, Abdulkadir Gokce, Badr AlKhamissi, Antoine Bosselut, Antonio Laverghetta Jr., Lonneke van der Plas, Roger E. Beaty Preprint, 2026 We found that LLMs capture aspects of the neural geometry of human creative thought, and that creativity-focused post-training preserves alignment with highly creative neural responses while reasoning-focused training shifts it away. |
|
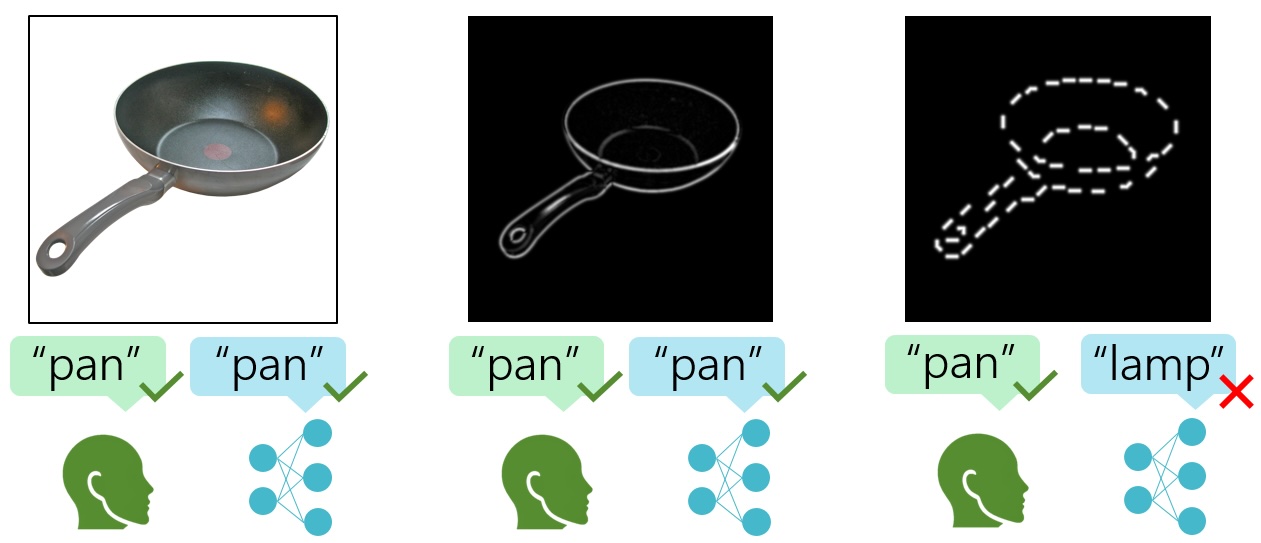
Contour Integration Underlies Human-Like Vision
Ben Lonnqvist, Elsa Scialom*, Abdulkadir Gokce*, Zehra Merchant, Michael Herzog, Martin Schrimpf ICML, 2025 We find that contour integration, a core feature of human object recognition, emerges in models only at large scales and correlates with improved shape bias. |
|
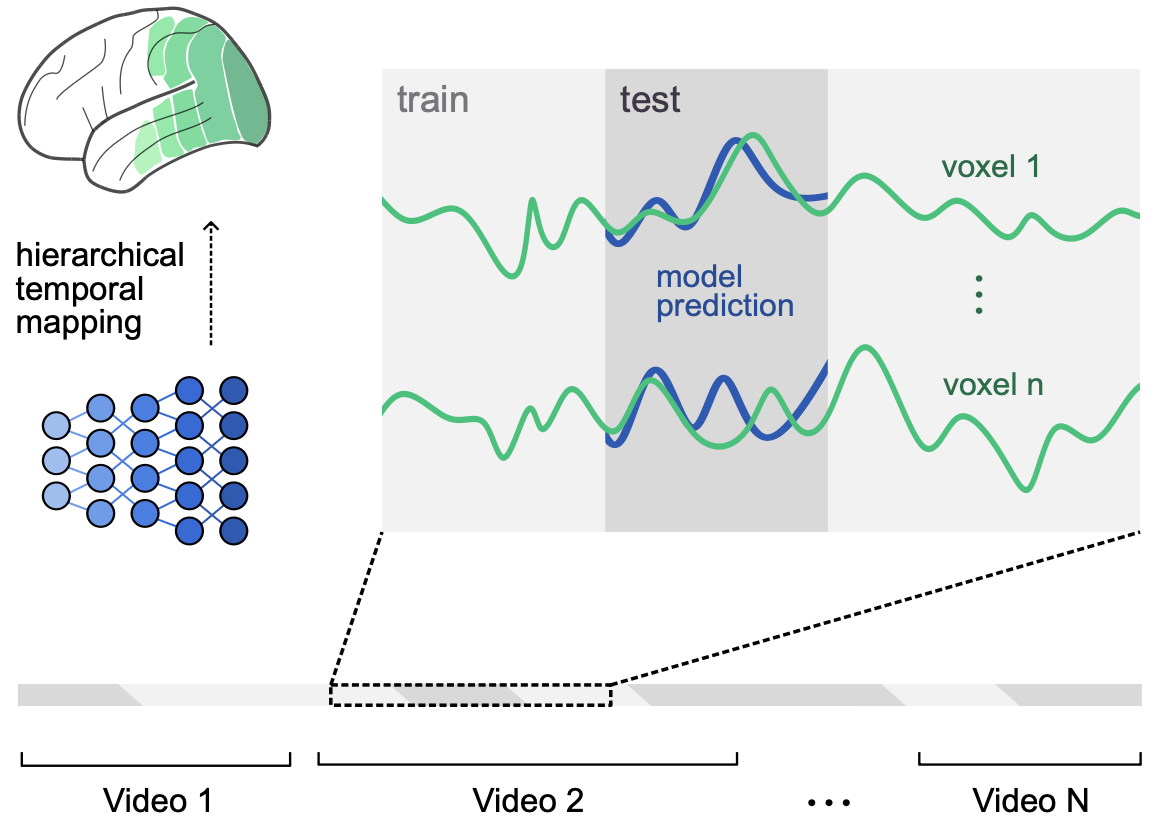
Dynamic Modelling of Visual Perception Is Governed by a Low-Dimensional Task Space
Yingtian Tang, Abdulkadir Gokce, K. J. Al-Karkari, Daniel Yamins, Martin Schrimpf Preprint, 2025 We found that the most brain-like video models capture human visual cortex through two core computations — object recognition and appearance-free motion recognition — which together organize visual processing across cortical streams. |
|
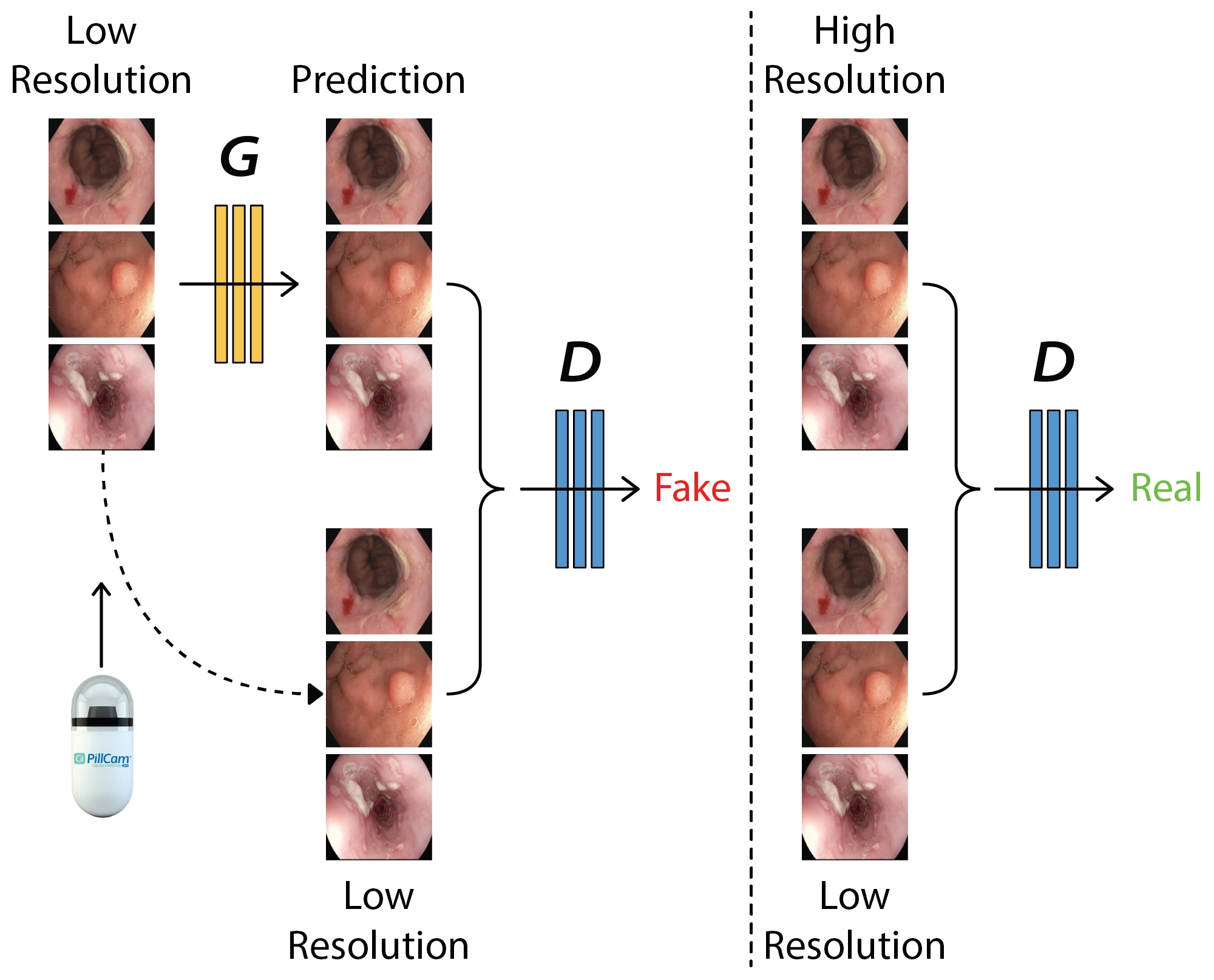
EndoL2H: Deep Super-Resolution for Capsule Endoscopy
Yasin Almalioglu, Kutsev Bengisu Ozyoruk, Abdulkadir Gokce, Kagan Incetan, Guliz Irem Gokceler, Muhammed Ali Simsek, Kivanc Ararat, Richard J Chen, Nicholas J Durr, Faisal Mahmood, Mehmet Turan IEEE Transactions on Medical Imaging EndoL2H enhances capsule endoscopy images up to 12x using a spatial attention-guided GAN, outperforming existing methods in perceptual quality and clinical relevance. |